Lectura de Data#
Hasta ahora, los datos que hemos utilizado han sido ingresados a mano. En situaciones reales esto no es lo más habitual y menos aún lo más deseable. Generalmente, los datos que se necesitan están disponibles en un archivo de texto, una planilla Excel o una base de datos.
Vamos a ver como leer data almacenada en un archivo de texto.
Leer un Archivo de Texto#
En el archivo data/TablaDesarrolloBtu0200335.csv se ha la tabla de desarrollo del BTU0200335. La estructura del archivo es la siguiente:
numero,fecha,interes,amortizacion,flujo,capital_insoluto
0,01-03-15,0,0,0,100
1,01-09-15,1,0,1,100
2,01-03-16,1,0,1,100
3,01-09-16,1,0,1,100
4,01-03-17,1,0,1,100
5,01-09-17,1,0,1,100
En la celda anterior, podemos ver las 5 primeras líneas del archivo (los datos on los correctos, pero el archivo no tiene líneas vacías entre cada línea con datos).
Se observa que la primera línea del archivo tiene unos títulos o encabezados, precisamente:
numero (se refiere al número del cupón)
fecha (se refiere a la fecha de fin de devengo del cupón. Si cae día hábil esta fecha coincide con la fecha de pago del cupón. Cuando esta fecha es inhábil, el cupón se paga al día hábil siguiente usando el valor de la UF del día hábil siguiente).
amortizacion
flujo
capital insoluto
El significado de los 3 últimos campos es claro. Se observa también que entre título y título hay una , . Este caracter sirve de separador, permite a quien lee el archivo saber cuando termina un título y empieza otro.
Finalmente, en las filas siguientes vemos la data propiamente tal.
Leer Todo el Archivo de una Vez#
Vamos a leer el archivo y luego revisamos el código.
with open('data/TablaDesarrolloBtu0200335.csv', 'r') as archivo:
tabla_1 = archivo.read()
print(tabla_1)
version https://git-lfs.github.com/spec/v1
oid sha256:b701bf8f368b63f03f1e14fc8d2756aeb6f28aeb2424a0b0b73a89af56320951
size 950
open('data/TablaDesarrolloBtu0200335.csv', 'r'): abre el archivo en modo sólo lecturar. Esto último porque sólo queremos leer data y no escribir nada en el archivo.with open(...) as archivo:rodear la instrucción
openconwith .... as <nombre archivo>nos asegura que una vez que terminemos de usar el archivo éste se cerrará automáticamente. Esto evita todos los problemas de tipo “Archivo está siendo utilizado por otro usuario”.
Si no se usa with ... as hay que proceder de la siguiente forma:
f = open('data/TablaDesarrolloBtu0200335.csv', 'r')
tabla_1 = f.read()
f.close()
O sea, hay que agregar la instrucción close que asegura que el archivo (o recurso) se libera. Esto último es fácil de olvidar, por eso la forma recomendada es utilizando with ... as.
Leer Línea a Línea#
Como antes, veamos la instrucción y luego la explicamos:
with open('data/TablaDesarrolloBtu0200335.csv', 'r') as archivo:
tabla_2 = archivo.readlines()
print(tabla_2)
['version https://git-lfs.github.com/spec/v1\n', 'oid sha256:b701bf8f368b63f03f1e14fc8d2756aeb6f28aeb2424a0b0b73a89af56320951\n', 'size 950\n']
readlines()lee cada una de las líneas del archivo y las almacena en unaList[str]donde cada elemento de laListes una de las líneas del archivo.notar que todas las líneas menos la última terminan con
\n. Estos dos caracteres indican un Enter o salto de línea.
Limpiar el Salto de Línea#
Vamos a remover el salto de línea.
with open('data/TablaDesarrolloBtu0200335.csv', 'r') as archivo:
tabla_2 = archivo.readlines()
tabla_3 = [(linea.rstrip('\n')) for linea in tabla_2] # rstrip() (right strip) es el método de str
# que hace la magia
print(tabla_3)
['version https://git-lfs.github.com/spec/v1', 'oid sha256:b701bf8f368b63f03f1e14fc8d2756aeb6f28aeb2424a0b0b73a89af56320951', 'size 950']
se define una nueva
List,tabla_2que almacenará las líneas limpias.se aplica el método
rstripa cada una de las líneas del archivo. Este método tiene el efecto deseado. Las líneas limpias se almacenan en la nuevaList,tabla_3.
NOTA: el segundo registro en realidad no es un cupón, es la manera que tiene el proveedor de la data de expresar la fecha de inicio de devengo del primer cupón.
Almacenar la Data en una Estructura Adecuada#
Si bien ahora tenemos las notas en un List, el formato no es muy cómodo.
El primer elemento (encabezados es distinto de todos los demás)
los datos específicos de cada cupón hay que buscarlos por posición,
están, además, todas las , .
Vamos a ver como traspasar la data a una List. Cada elemento de esta List será de este tipo Dict[str, float]]. O sea un Dictcuyas keys son los nombres de los encabezados y cuyos values son los valores que corresponden a cada encabezado.
Extraemos los Encabezados#
Se extraerán los encabezados y se almacenarán en una List.
encabezados = tabla_3[0].split(',')
encabezados
['version https://git-lfs.github.com/spec/v1']
El método split(',') separa los elementos de un str suponiendo que el caracter que los separa es ',' y los almacena en una List[str].
Procesamos los Cupones#
Podemos hacer el mismo procesamiento para la data de cada cupón.
cupones = [c.split(',') for c in tabla_3[2:]]
cupones[0:5]
[['size 950']]
Se Termina#
Finalmente, construimos el Dict requerido.
tabla = [{encabezados[0]: int(c[0]),
encabezados[1]: c[1],
encabezados[2]: float(c[2]),
encabezados[3]: float(c[3]),
encabezados[4]: float(c[4]),
encabezados[5]: float(c[5])} for c in cupones]
tabla
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[7], line 1
----> 1 tabla = [{encabezados[0]: int(c[0]),
2 encabezados[1]: c[1],
3 encabezados[2]: float(c[2]),
4 encabezados[3]: float(c[3]),
5 encabezados[4]: float(c[4]),
6 encabezados[5]: float(c[5])} for c in cupones]
7 tabla
Cell In[7], line 1, in <listcomp>(.0)
----> 1 tabla = [{encabezados[0]: int(c[0]),
2 encabezados[1]: c[1],
3 encabezados[2]: float(c[2]),
4 encabezados[3]: float(c[3]),
5 encabezados[4]: float(c[4]),
6 encabezados[5]: float(c[5])} for c in cupones]
7 tabla
ValueError: invalid literal for int() with base 10: 'size 950'
Ejercicio#
Calcular el valor presente del bono a una TIR de mercado del 1.85% al 2021-07-30.
Rápidamente nos damos cuenta del siguiente problema, la fecha de pago de cada cupón está en un formato (str) que no permite calcular directamente el plazo residual de cada cupón. Vamos a solucionarlo utilizando algunas funciones del paquete datetime.
Primero un par de ejemplos:
Variable de tipo date:
from datetime import date
fecha = date(2021, 7, 30) # Definimos el 30 de julio del 2021 como variable
print(f'Día: {fecha.day}')
print(f'Mes: {fecha.month}')
print(f'Año: {fecha.year}')
print(f'Formato ISO: {fecha.isoformat()}')
print(f'Día de la semana: {fecha.weekday()}') # En esta librería el lunes es el número 0
Día: 30
Mes: 7
Año: 2021
Formato ISO: 2021-07-30
Día de la semana: 4
Obtener una variable de tipo date a partir de un str:
from datetime import datetime
otra_fecha = datetime.strptime('01-02-22', '%d-%m-%y')
print(f"Con horas, minutos y segundos: {otra_fecha}")
print()
otra_fecha = otra_fecha.date()
print(f"Sólo fecha: {otra_fecha}")
Con horas, minutos y segundos: 2022-02-01 00:00:00
Sólo fecha: 2022-02-01
Calcular la diferencia en días entre dos fechas:
dif_en_dias = otra_fecha - fecha
print(type(dif_en_dias))
print(dif_en_dias.days)
<class 'datetime.timedelta'>
186
Con estos nuevos elementos, vamos a transformar todas las fechas finales de los cupones del bono en variables de tipo date.
for c in tabla:
c['fecha'] = datetime.strptime(c['fecha'], '%d-%m-%y').date()
print(tabla[0])
{'numero': 1, 'fecha': datetime.date(2015, 9, 1), 'interes': 1.0, 'amortizacion': 0.0, 'flujo': 1.0, 'capital_insoluto': 100.0}
Ahora sí podemos calcular el plazo residual de cada cupón respecto a la fecha de valorización.
plazos = [(c['fecha'] - fecha).days for c in tabla]
plazos
[-2159,
-1977,
-1793,
-1612,
-1428,
-1247,
-1063,
-882,
-698,
-516,
-332,
-151,
33,
214,
398,
579,
763,
945,
1129,
1310,
1494,
1675,
1859,
2040,
2224,
2406,
2590,
2771,
2955,
3136,
3320,
3501,
3685,
3867,
4051,
4232,
4416,
4597,
4781,
4962]
También podemos obtener una List con los flujos:
flujos = [c['flujo'] for c in tabla]
flujos
[1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
1.0,
101.0]
Tenemos ahora los plazos residuales de los bonos y sus flujos, será ideal poder reciclar la función de valorización que escribimos la clase pasada.
Warning
¿Qué hacemos? ¿Cut & Paste? Eso jamás, copiar y pegar el mismo código en partes distintas te asegura que en el futuro tendrás un problema de coherencia.
En el archivo my_functions.py se ha copiado la función. De ahora en adelante, cuando queramos utilizarla, importaremos este archivo. De la misma forma, cualquier cambio o mejora que le hagamos, se verá inmediatamente reflejado en todos los lugares en donde se esté utilizando.
import my_functions as fn
tasa = .0185
vp = fn.vp_bono(flujos, plazos, tasa)
print(f"Valor presente al {tasa: .2%}: {vp:,.6f}")
Valor presente al 1.85%: 115.432309
¿Se ve raro verdad? Demasiado alto. Es porque nuestra función no distingue los plazos residuales negativos. En el mismo módulo, hay una segunda versión que sí lo hace.
vp_2 = fn.vp_bono_2(flujos, plazos, tasa)
print(f"Valor presente al {tasa: .2%}: {vp_2:,.6f}")
Valor presente al 1.85%: 102.709384
La Librería pandas#
Referencia: https://pandas.pydata.org/pandas-docs/stable/index.html
Esta es una librería de Python que sirve para manejar data en forma tabular. Por ejemplo, veamos lo fácil que resulta importar el archivo TablaDesarrolloBtu0200335.csv.
La manera acostumbrada de importar esta librería es utilizando import pandas as pd. Es importante saber que pandas no es parte de la librería estándar de Python, por eso, para utilizarla, debe estar instalada en el entorno en el que se está trabajando. En particular, pandas está instalada en el entorno de ejecución de estos notebooks.
import pandas as pd
Para importar el archivo con la tabla de desarrollo.
df_tabla = pd.read_csv(
'data/TablaDesarrolloBtu0200335.csv', # Ruta completa del archivo.
sep=',', # Caracter que actúa de separador de columnas.
dtype={
'numero': int, # Se declara el tipo de los datos en cada columna.
'interes': float, # No es imprescindible, pero sí es recomendable.
'amortizacion': float,
'flujo': float,
'capital_insoluto': float
}
)
df_tabla.dtypes
numero int64
fecha object
interes float64
amortizacion float64
flujo float64
capital_insoluto float64
dtype: object
df_tabla
| numero | fecha | interes | amortizacion | flujo | capital_insoluto | |
|---|---|---|---|---|---|---|
| 0 | 0 | 01-03-15 | 0.0 | 0.0 | 0.0 | 100.0 |
| 1 | 1 | 01-09-15 | 1.0 | 0.0 | 1.0 | 100.0 |
| 2 | 2 | 01-03-16 | 1.0 | 0.0 | 1.0 | 100.0 |
| 3 | 3 | 01-09-16 | 1.0 | 0.0 | 1.0 | 100.0 |
| 4 | 4 | 01-03-17 | 1.0 | 0.0 | 1.0 | 100.0 |
| 5 | 5 | 01-09-17 | 1.0 | 0.0 | 1.0 | 100.0 |
| 6 | 6 | 01-03-18 | 1.0 | 0.0 | 1.0 | 100.0 |
| 7 | 7 | 01-09-18 | 1.0 | 0.0 | 1.0 | 100.0 |
| 8 | 8 | 01-03-19 | 1.0 | 0.0 | 1.0 | 100.0 |
| 9 | 9 | 01-09-19 | 1.0 | 0.0 | 1.0 | 100.0 |
| 10 | 10 | 01-03-20 | 1.0 | 0.0 | 1.0 | 100.0 |
| 11 | 11 | 01-09-20 | 1.0 | 0.0 | 1.0 | 100.0 |
| 12 | 12 | 01-03-21 | 1.0 | 0.0 | 1.0 | 100.0 |
| 13 | 13 | 01-09-21 | 1.0 | 0.0 | 1.0 | 100.0 |
| 14 | 14 | 01-03-22 | 1.0 | 0.0 | 1.0 | 100.0 |
| 15 | 15 | 01-09-22 | 1.0 | 0.0 | 1.0 | 100.0 |
| 16 | 16 | 01-03-23 | 1.0 | 0.0 | 1.0 | 100.0 |
| 17 | 17 | 01-09-23 | 1.0 | 0.0 | 1.0 | 100.0 |
| 18 | 18 | 01-03-24 | 1.0 | 0.0 | 1.0 | 100.0 |
| 19 | 19 | 01-09-24 | 1.0 | 0.0 | 1.0 | 100.0 |
| 20 | 20 | 01-03-25 | 1.0 | 0.0 | 1.0 | 100.0 |
| 21 | 21 | 01-09-25 | 1.0 | 0.0 | 1.0 | 100.0 |
| 22 | 22 | 01-03-26 | 1.0 | 0.0 | 1.0 | 100.0 |
| 23 | 23 | 01-09-26 | 1.0 | 0.0 | 1.0 | 100.0 |
| 24 | 24 | 01-03-27 | 1.0 | 0.0 | 1.0 | 100.0 |
| 25 | 25 | 01-09-27 | 1.0 | 0.0 | 1.0 | 100.0 |
| 26 | 26 | 01-03-28 | 1.0 | 0.0 | 1.0 | 100.0 |
| 27 | 27 | 01-09-28 | 1.0 | 0.0 | 1.0 | 100.0 |
| 28 | 28 | 01-03-29 | 1.0 | 0.0 | 1.0 | 100.0 |
| 29 | 29 | 01-09-29 | 1.0 | 0.0 | 1.0 | 100.0 |
| 30 | 30 | 01-03-30 | 1.0 | 0.0 | 1.0 | 100.0 |
| 31 | 31 | 01-09-30 | 1.0 | 0.0 | 1.0 | 100.0 |
| 32 | 32 | 01-03-31 | 1.0 | 0.0 | 1.0 | 100.0 |
| 33 | 33 | 01-09-31 | 1.0 | 0.0 | 1.0 | 100.0 |
| 34 | 34 | 01-03-32 | 1.0 | 0.0 | 1.0 | 100.0 |
| 35 | 35 | 01-09-32 | 1.0 | 0.0 | 1.0 | 100.0 |
| 36 | 36 | 01-03-33 | 1.0 | 0.0 | 1.0 | 100.0 |
| 37 | 37 | 01-09-33 | 1.0 | 0.0 | 1.0 | 100.0 |
| 38 | 38 | 01-03-34 | 1.0 | 0.0 | 1.0 | 100.0 |
| 39 | 39 | 01-09-34 | 1.0 | 0.0 | 1.0 | 100.0 |
| 40 | 40 | 01-03-35 | 1.0 | 100.0 | 101.0 | 0.0 |
df_tabla.head() # <DataFrame>.head(n) muestra los primeros n registros.
| numero | fecha | interes | amortizacion | flujo | capital_insoluto | |
|---|---|---|---|---|---|---|
| 0 | 0 | 01-03-15 | 0.0 | 0.0 | 0.0 | 100.0 |
| 1 | 1 | 01-09-15 | 1.0 | 0.0 | 1.0 | 100.0 |
| 2 | 2 | 01-03-16 | 1.0 | 0.0 | 1.0 | 100.0 |
| 3 | 3 | 01-09-16 | 1.0 | 0.0 | 1.0 | 100.0 |
| 4 | 4 | 01-03-17 | 1.0 | 0.0 | 1.0 | 100.0 |
La columna fecha se importa como un str (tipo obj). Luego veremos como transformarla en un objeto de tipo date.
df_tabla.dtypes
numero int64
fecha object
interes float64
amortizacion float64
flujo float64
capital_insoluto float64
dtype: object
A medida que las vayamos necesitando, veremos muchas más funcionalidades de pandas. Para los que quieran avanzar desde ya, recomiendo partir leyendo un tutorial específico como el siguiente: https://www.learndatasci.com/tutorials/python-pandas-tutorial-complete-introduction-for-beginners/
Leer un Archivo Excel#
Muchas veces, la data que se requiere procesar está almacenada en un archivo Excel. Para estos casos, pandas suele ser lo más conveniente.
df_tabla_2 = pd.read_excel(
'data/TablaDesarrolloBtu0200335.xlsx',
dtype={
'numero': int, # Se declara el tipo de los datos en cada columna.
'interes': float, # No es imprescindible, pero sí es recomendable.
'amortizacion': float,
'flujo': float,
'capital_insoluto': float,
})
df_tabla_2.head()
| numero | fecha | interes | amortizacion | flujo | capital_insoluto | |
|---|---|---|---|---|---|---|
| 0 | 0 | 2015-03-01 | 0.0 | 0.0 | 0.0 | 100.0 |
| 1 | 1 | 2015-09-01 | 1.0 | 0.0 | 1.0 | 100.0 |
| 2 | 2 | 2016-03-01 | 1.0 | 0.0 | 1.0 | 100.0 |
| 3 | 3 | 2016-09-01 | 1.0 | 0.0 | 1.0 | 100.0 |
| 4 | 4 | 2017-03-01 | 1.0 | 0.0 | 1.0 | 100.0 |
Por ejemplo, vemos que al importar desde Excel, la fecha queda con un tipo más adecuado.
df_tabla_2.dtypes
numero int64
fecha datetime64[ns]
interes float64
amortizacion float64
flujo float64
capital_insoluto float64
dtype: object
La Función vp_bono Usando un DataFrame#
Para hacer un loop sobre las filas de un DataFrame la manera recomendada es la siguiente:
for r in df_tabla_2.itertuples(): # Pensar en itertuples como las filas
print(r)
print()
print(f'Index: {r.Index}')
print(f'numero: {r.numero}')
print(f'fecha: {r.fecha}')
print(f'interes: {r.interes}')
print(f'amortizacion: {r.amortizacion}')
print(f'flujo: {r.flujo}')
print(f'capital_insoluto: {r.capital_insoluto}')
break
Pandas(Index=0, numero=0, fecha=Timestamp('2015-03-01 00:00:00'), interes=0.0, amortizacion=0.0, flujo=0.0, capital_insoluto=100.0)
Index: 0
numero: 0
fecha: 2015-03-01 00:00:00
interes: 0.0
amortizacion: 0.0
flujo: 0.0
capital_insoluto: 100.0
def vp_bono_df(bono, tasa, fecha):
"""
Calcula el valor presente de un bono dada una tasa de descuento.
Parameters
----------
bono: pandas.DataFrame
Contiene la tabla de desarrollo del bono. Tiene que tener una columna `fecha` con las fechas
finales de cada cupón y una columna `flujo` con el flujo total del cupón.
tasa: float
Tasa de descuento del bono. Debe ser en convención Com Act/365.
fecha: datetime.date
Fecha a la cual se realiza la valorización. Todos los cupones con fecha final menor a `fecha` tendrán
un valor presente igual a 0. Los cupones con fecha final superior a `fecha` serán descontados por el
plazo efectivo en días desde `fecha`hasta su fecha final.
Returns
-------
float
El valor presente del bono.
"""
result = 0.0
# Vamos a hacer un loop sobre las filas del `DataFrame`
for r in bono.itertuples():
# El método date transforma el datetime a una fecha (sin la hora)
plazo = r.fecha.date() - fecha # Se calcula el plazo residual del flujo
if plazo.days > 0: # Si el plazo es positivo se calcula el valor presente
result += r.flujo * (1 + tasa)**(-plazo.days / 365.0)
return result
vp = vp_bono_df(df_tabla_2, tasa, fecha)
print(f'Valor presente: {vp: ,.4f}')
Valor presente: 102.7094
Ejercicio: Valor Par de un Bono Chileno#
La TERA del BTU0200335 es 2.0085%. Escribir una función para calcular el Valor Par del bono según la convención de la Bolsa de Comercio. La fórmula para el cálculo del Valor Par es:
donde \(d\) es el número de días corridos desde la fecha final del último cupón pagado y la fecha de cálculo.
En Chile el precio de un instrumento de renta fija está definido como:
Luego, el monto a pagar por el bono transado a \(TirMkt\) se calcula como:
Primeramente, vamos a definir una función que nos ayudará a encontrar la fecha de inicio del cupón corriente. Se aconseja recordar este ejemplo ya que es de mucha utilidad en renta fija. Por ejemplo, en los análisis donde se requiere clasificar en bandas temporales un conjunto de flujos de caja.
import bisect # Es parte de la librería estándar de Python.
def find_le(a, x):
"""
Find rightmost value less than or equal to x.
Esta función está copiada directamente de la documentación de la librería `bisect`.
"""
i = bisect.bisect_right(a, x)
if i:
return a[i - 1]
raise ValueError("x is less than leftmost element in a.")
a = [1, 2, 3, 4.1, 5, 6, 7, 8]
x = 4.5
find_le(a, x)
4.1
def valor_par(bono, fecha, tera):
"""
El desafío es identificar cuál es el cupón vigente. Luego, conociendo la fecha de inicio
del cupón vigente, se puede calcular d y luego aplicar la fórmula.
Parameters
----------
bono: pandas.DataFrame
Es la tabla de desarrollo del bono. El DataFrame debe tener una columna 'fecha' de tipo `datetime` y una
columna 'capital_insoluto' de tipo `float` o `int`.
fecha: datetime.date
Fecha a la cual se requiere el cálculo.
tera: float
Tera del bono.
Returns
-------
Un float resultado del cálculo de valor par.
"""
# Construimos una `List` con las fechas de inicio de todos los cupones.
fechas_inicio = [row.fecha.date() for row in bono.itertuples()]
# Se verifica que `fecha` no sea posterior al vencimiento del bono.
if fecha >= fechas_inicio[-1]:
raise ValueError('fecha es posterior al vencimiento del bono.')
# Con la función de ayuda definida más arriba encontramos la fecha de inicio del cupón corriente.
fecha_inicio_ok = find_le(fechas_inicio, fecha)
# Luego determinamos el saldo insoluto
saldo = bono[bono['fecha'] == fecha_inicio_ok.isoformat()]['capital_insoluto'].iloc[0]
# Se calcula el número de días.
d = (fecha - fecha_inicio_ok).days
return saldo * (1 + tera)**(d / 365.0)
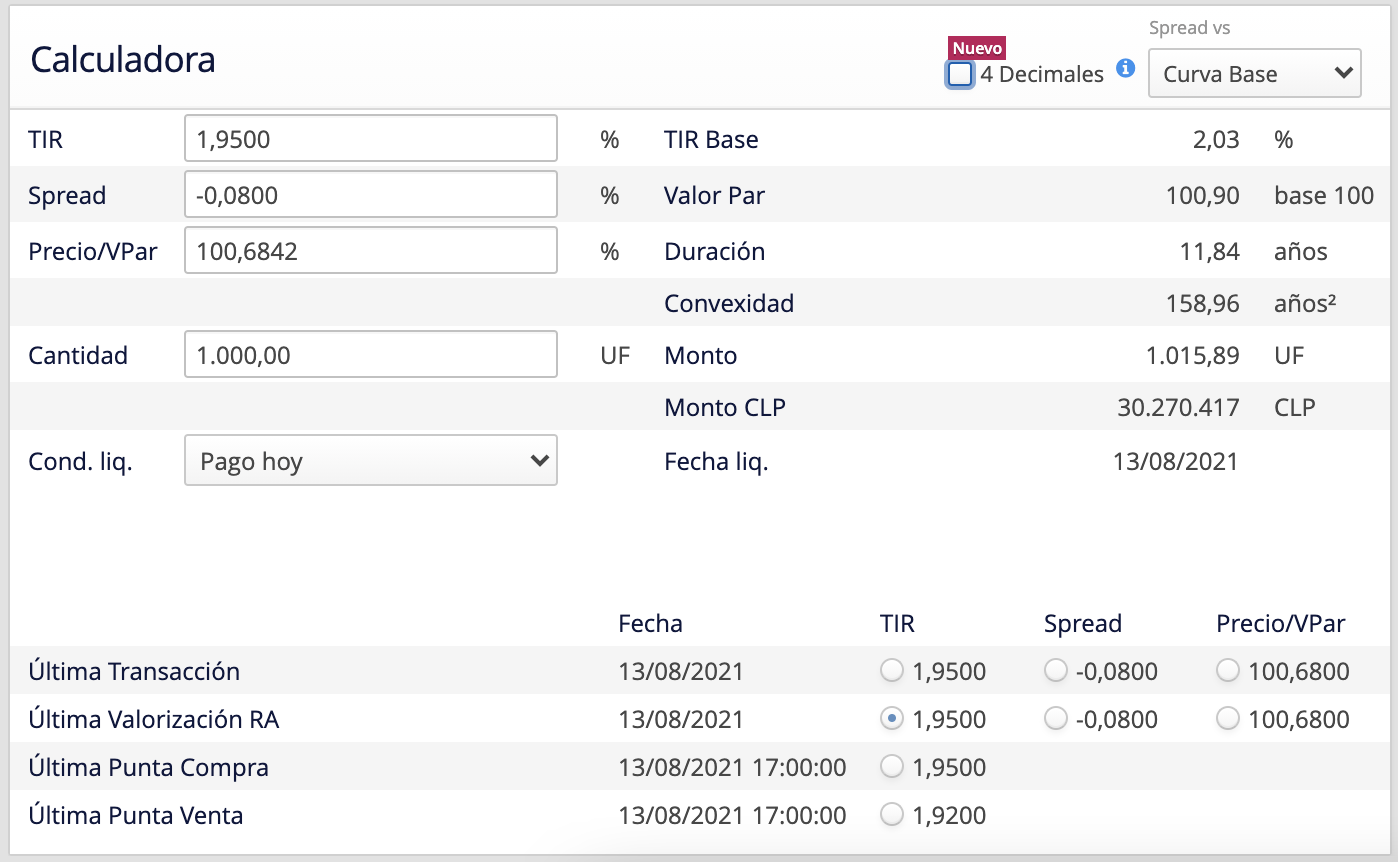
tera = .020085
fecha_valor = date(2021, 8, 13)
vpar = valor_par(df_tabla_2, fecha_valor, tera)
vpar
np.float64(100.90300695613934)
Bonus Points#
Primero se calcula el valor presente utilizando la función vp_bono_df definida más arriba.
tir = .0195
vpresente = vp_bono_df(df_tabla_2, tir, fecha_valor)
vpresente
101.59334113363484
Luego calculamos el precio sin redondear:
precio = vpresente / vpar
Finalmente, se muestra el precio redondeado a 2 y 4 decimales:
print(f'Precio a 2 decimales: {precio: .2%}')
print(f'Precio a 6 decimales: {precio: .4%}')
Precio a 2 decimales: 100.68%
Precio a 6 decimales: 100.6842%
Se compara con RiskAmerica.